Sii Ukraine
SII POLAND
SII SWEDEN
Sii Ukraine


SII POLAND


SII SWEDEN

Sii Ukraine
SII POLAND
SII SWEDEN
Заповніть форму англійською мовою

Ми зв'яжемося з вами, як тільки переглянемо ваше резюме
Оновіть сторінку та спробуйте ще раз. Зв'яжіться з нами, якщо проблема виникне знову
Спробуйте завантажити іншу копію або нову версію файлу. Зверніться до нас, якщо проблема повториться.
Ми зв'яжемося з вашим другом, як тільки переглянемо резюме
Оновіть сторінку та спробуйте ще раз. Зв'яжіться з нами, якщо проблема виникне знову
Спробуйте завантажити іншу копію або нову версію файлу. Зверніться до нас, якщо проблема повториться.
Ми зв'яжемося з вами, як тільки переглянемо ваше резюме
Ми зв'яжемося з вашим другом, як тільки переглянемо резюме
Хочете розвивати свої компетенції у сфері хмарних технологій? Приєднуйтесь до нашого спеціалізованого підрозділу, що об’єднує експертів у галузі обробки та аналізу даних у рамках Компетентного центру Data & Analytics. Ми також пропонуємо можливості для розвитку у сферах Data Science, Big Data та Machine Learning.
Вакансія № 260615-RJTX3
Sii ensures that all hiring decisions are made solely on the basis of qualifications and competence. We are committed to equal and fair treatment of all, regardless of legally protected characteristics. At Sii, we promote a diverse and inclusive work environment, in full compliance with applicable anti-discrimination laws.
Are you looking to develop your skills in cloud technologies? Join our specialized unit, which brings together experts in data processing and analysis within the Data & Analytics Competence Center. We also offer opportunities for professional growth in the fields of Data Science, Big Data, and Machine Learning.
Job no. 260615-RJTX3
Sii ensures that all hiring decisions are made solely on the basis of qualifications and competence. We are committed to equal and fair treatment of all, regardless of legally protected characteristics. At Sii, we promote a diverse and inclusive work environment, in full compliance with applicable anti-discrimination laws.
Fill in the form in English please
Інженер з хмарних даних (ж/ч/х)
Ми зв'яжемося з вами, як тільки переглянемо ваше резюме
Оновіть сторінку та спробуйте ще раз. Зв'яжіться з нами, якщо проблема виникне знову
Спробуйте завантажити іншу копію або нову версію файлу. Зверніться до нас, якщо проблема повториться.

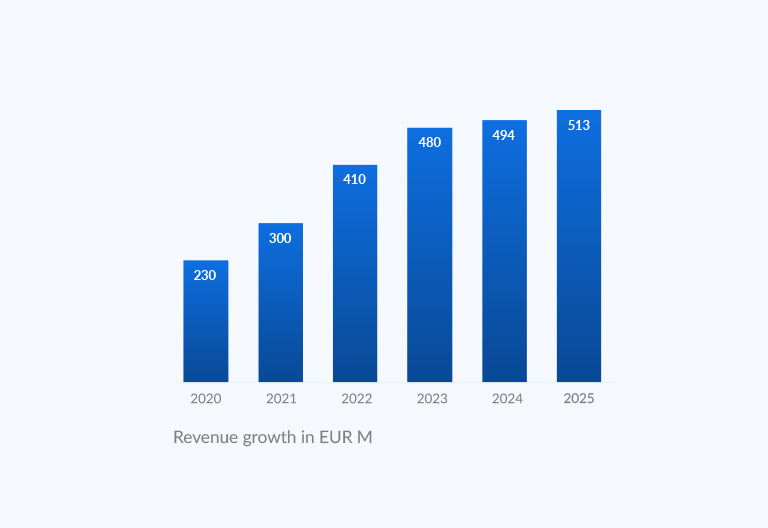









У нас є більше пропозицій
Wir aktualisieren unsere deutsche Website. Wenn Sie die Sprache wechseln, wird Ihnen die vorherige Version angezeigt.
Are you sure you want to leave this page?
Are you sure you want to leave this page?











